第9回 コレスポンデンス分析の結果を解釈する上での注意点(2008.11.1)
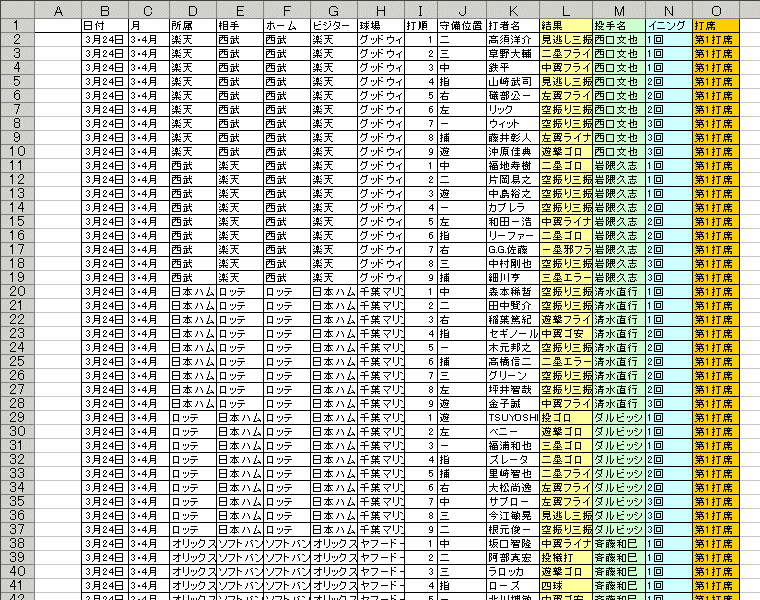
| ・B列:日付 | その試合が行われた日付である。 | |||||||||
| ・C列:月 | B列の日付から月だけに絞ったものである。 3~4月、5月、6月、7月、8月、9~10月の6つで分類している。 | |||||||||
| ・D列:所属 | K列の打者の所属するチームである。言うまでもなく12球団で分類している。 | |||||||||
| ・E列:相手 | L列の投手の所属するチームである。こちらも12球団で分類している。 | |||||||||
| ・F列:ホーム | その試合のホームのチームである。同じく12球団で分類している。 | |||||||||
| ・G列:ビジター | その試合のビジターのチームである。同じく12球団で分類している。 | |||||||||
| ・H列:球場 | その試合が開催された球場である。各球団の本拠地球場だけでなく地方球場も含まれている。 | |||||||||
| ・I列:打順 | その試合のスタメン時の打順である。途中出場の選手は空白にしている。 | |||||||||
| ・J列:守備位置 | その試合の守備位置である。 スタメンや途中出場関係なく、その試合でついた全ての守備位置を網羅している。 | |||||||||
| ・K列:打者名 | その試合に出場して打撃機会のあった打者を記載しているので、守備固めで出場して打席に立たなかった選手は含まれない。 | |||||||||
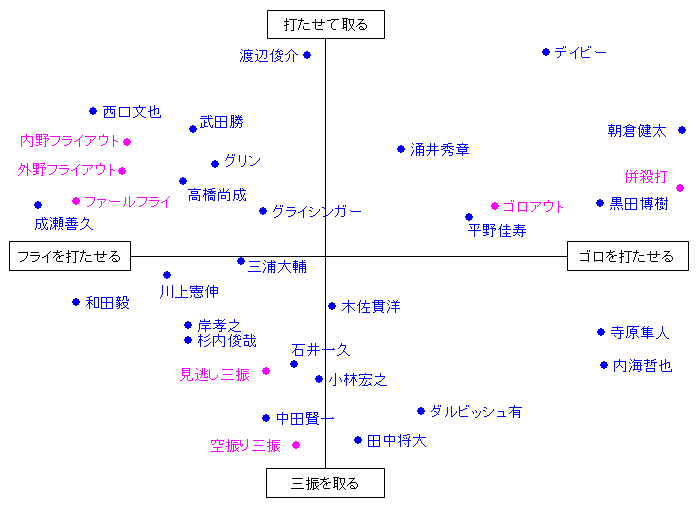
| ・L列:結果 | その打席での結果である。 単なる安打やアウトの分類だけでなく打球方向なども網羅しているため、全部132通りに分類されている。 コレスポンデンス分析の際には、アウトだけを抜き出して、1塁フライや2塁フライなどはまとめて内野フライアウトに、のように大きなカテゴリーに分類し直している。 | |||||||||
| ・M列:投手名 | その試合に登板して打者と対戦機会のあった投手を記載している。 | |||||||||
| ・N列:イニング | その試合で打者と投手が対戦したイニングを記載している。 言うまでもなく、1回から12回までに分類している。表と裏には分類していない。 | |||||||||
| ・O列:打席 | その試合で打者と投手が対戦したイニングを記載している。 第1打席から第7打席までの他に、代打出場の場合は別途「代打」として分類している。 | |||||||||